如何设计与实现一个分布式索引框架(一):概览
这是一个系列文章,大部分内容都来自我过去在小红书发现 Feed 团队工作期间的实践和经验。在介绍的过程中我会尽量不掺杂过多的业务细节1,而专注于这背后我个人一些浅薄的设计思想,希望你在阅读完这些文章以后能够直接或者间接地拓展到不同的场景。
在介绍什么是索引框架之前先了解一下我们当时面临的业务场景2,业界现在的 feed 流产品已经逐步从非个性化全面过渡到个性化,所谓的个性化 feed 其实就是基于机器学习的推荐系统。
先讲讲什么是推荐系统,用一个词概括就是「投其所好」。当你遇到一个跟你志趣相投的人时,那这个人感兴趣的东西很有可能也是你感兴趣的,这是「基于人」的维度进行推荐,微信的「朋友圈」就是这么一个简单的思路3。也有可能一个人他从来没见过你,你们也不互相认识,但是如果他能够知道你过去看过、喜欢过的东西,那他也很有可能可以推断出你未来感兴趣的东西,这是「基于历史行为」的维度进行推荐。我们可以通过制定一些人工的规则来实现推荐,但是用户的喜好是千奇百怪的4,有大量长尾的需求是人工规则无法覆盖的5。因此我们需要让计算机学习如何制定这些规则,这是对「机器学习」这个概念非常浅显的解释。一个完整的机器学习流程简单概括包含「离线」和「在线」两部分,离线部分是通过大量的用户数据来让计算机找寻其中的规律和共性,最终产出「模型」;在线部分是通过输入当前用户的数据给模型,让模型计算出一个预测值,这个预测值用来衡量我们想要推荐的内容是否符合这个用户的兴趣。这个系列的文章将会主要围绕在线部分,离线部分如果有机会会在以后的文章中介绍。
前面提到在线部分的核心逻辑是模型计算6,但在计算之前还有一个非常重要的工作是筛选候选集,通常叫做「召回(recall)」。所谓召回就是从一个很大的集合中通过一定的条件选取一个子集,为什么要有召回这一步呢?本质上是因为模型计算是一个非常耗费时间及资源的过程,如果每次用户请求都对整个集合中的条目进行计算,不仅浪费资源,所需的时间对于用户来说也是无法接受的7。大部分情况8下我们对于推荐系统一次请求的时间要求是控制在 100~200ms 左右,如果超过这个时间对业务指标一定会有负面影响。因此有针对性地进行召回就非常关键了,召回需要尽量确保筛选出来的候选集是符合当前用户兴趣的,但同时耗时又是非常短的9。总结一下一次推荐请求的流程如下图所示。
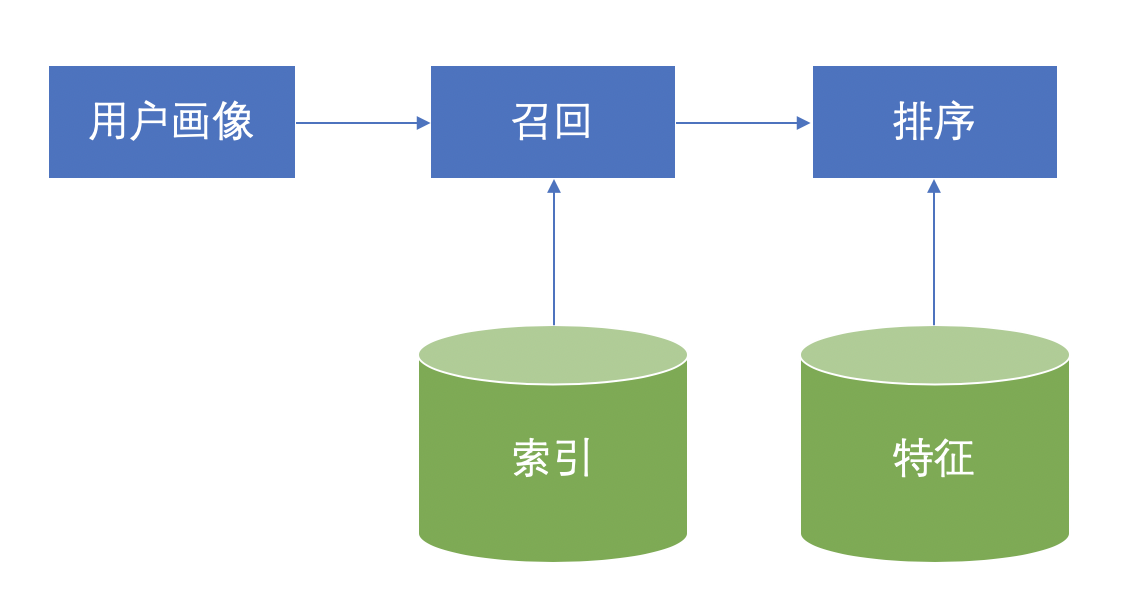
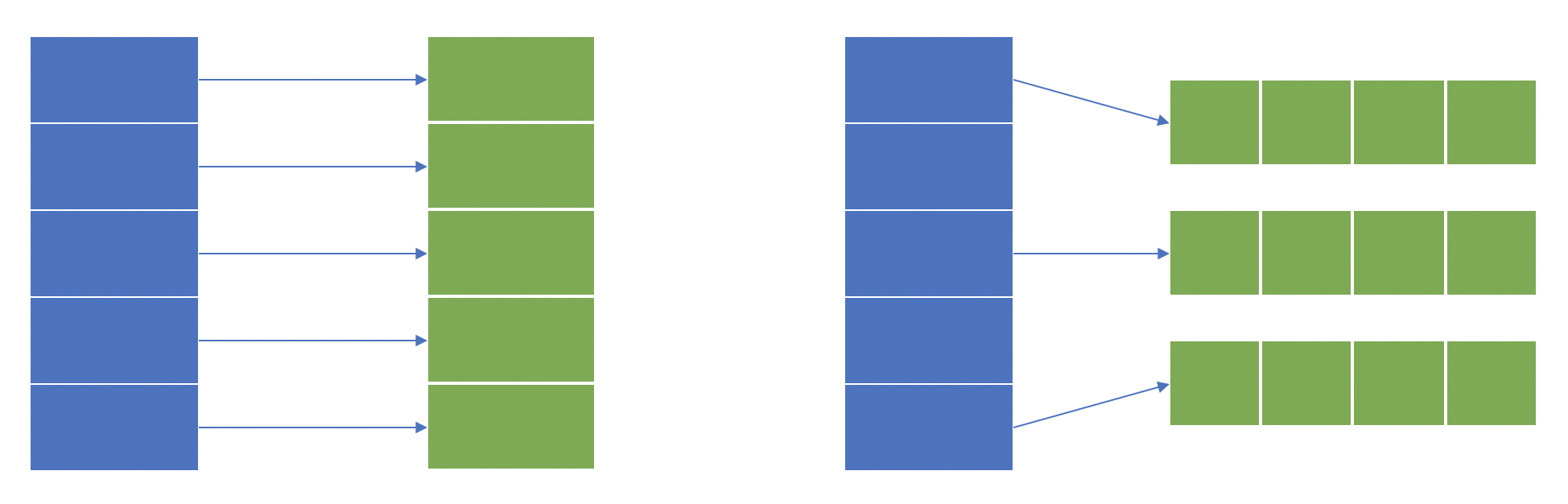
实现快速召回的关键是「索引(index)」,正如大部分数据库系统一样,索引是为了实现快速查找的重要组件。在推荐系统中主要有两类索引:正排索引(forward index)和倒排索引(inverted index)10。正排索引通常是用来通过一个主键(primary key)查询一个条目,是「一对一的映射」;倒排索引是用来通过跟条目关联的某些属性查询多个条目,是「一对多的映射」。举个实际的例子,小红书上用户发布的内容叫做「笔记」,每一篇笔记都会生成一个唯一的 ID,这个 ID 就是这篇笔记的主键,正排索引即是一个从笔记 ID 到笔记的映射。而每篇笔记都会有一些同笔记本身相关的属性,比如分类(category),一些常见的分类有:旅行、美妆、摄影、美食等。倒排索引即是一个从多个属性到多篇笔记的映射,如「旅行」分类可以映射到所有属于这个类别的笔记列表。对于召回来说主要依赖倒排索引,而正排索引将会在模型计算的前置步骤特征提取中用到11。
讲到这里也基本上把索引框架需要实现的功能介绍得差不多了,其实需求很简单:给定一个集合然后在这个集合上创建正排和倒排索引,并暴露相应的查询接口。下一篇将会详细介绍如何定义索引、框架的 API 应该有哪些以及如何实现一个简单的倒排索引。