如何设计与实现一个分布式索引框架(三):正排索引
这是一个系列文章,大部分内容都来自我过去在小红书发现 Feed 团队工作期间的实践和经验。在介绍的过程中我会尽量不掺杂过多的业务细节,而专注于这背后我个人一些浅薄的设计思想,希望你在阅读完这些文章以后能够直接或者间接地拓展到不同的场景。
上一篇文章介绍了如何定义 schema、查询 API 以及怎样实现倒排索引,本篇将会着重介绍另一种重要的索引类型「正排索引」,以及跟正排索引密切相关的「二级索引」。
正排索引
正排索引是主键(primary key)到条目的一一映射,在推荐系统中使用正排索引的场景是获取模型计算所需的原始特征(raw feature)。为什么说是原始特征呢?因为这些数据还需要经过特征提取(feature extraction)以后才能作为最终输入给模型的参数,特征提取不在本系列文章的讨论范畴。
这里先简单讲讲什么是特征。最早我们提到机器学习的时候讲过模型是首先经过离线训练产生,然后用于在线预测去预估用户的喜好。在离线训练阶段算法工程师需要先从训练数据1人工筛选出一批对于当前想要训练的模型有意义、有价值的、可衡量的属性,这个过程叫做「特征工程(feature engineering)」。特征工程考验的是一个算法工程师对于业务数据的理解、经验、数据敏感度以及统计分析能力,很多时候还需要结合大量的 A/B 实验才行。近年来深度学习的兴起已经将特征工程的复杂度降低不少,但特征工程依然是一个非常重要的步骤。这些被筛选出来的属性就是特征,举个直观的例子下面这些都可以作为模型特征使用:用户的地理位置、用户性别、用户看过的内容总曝光/点击/赞/评论的次数等。
正排索引中的条目存储的就是大量的原始特征,这些特征也是在 schema 中定义,基本上 schema 中除了跟倒排索引有关的字段其它都属于特征。因此可以看到正排索引条目的大小是远大于倒排索引条目的。为了保证查询的性能我们依然选择了将正排索引存储在内存中,但是这会带来一个问题��,因为正排索引占用的空间可能会很大,我们也是明确知道这些数据是需要常驻在内存中的,对于类似 Java 这种带有 GC 的语言来说这部分数据反而会增加垃圾回收器的压力。这些数据会长期存储在 old generation 中,不仅浪费空间也降低了 GC 的性能。那么我们的目标便是尽量不要让这部分数据对 GC 造成太大的影响,最好是对 GC 不可见的,毕竟「眼不见心不烦」。
一种比较常见的解决方案是「堆外内存(off-heap)」2。所谓堆外内存就是通过某些特殊的 API 分配独立的内存空间,且这个内存空间对于 GC 是不可见的,当然也就不会影响 GC。听起来这个方法似乎很简单直接,但凡事有好也有坏,绕开 GC 的副作用是你需要自己管理这块儿内存,如何高效地使用堆外内存是一个比较关键的问题。HBase 的 BucketCache3是一个值得参考的实现,我们在调研阶段也仔细研究过 BucketCache 的设计,但最终没有直接照搬,有一个非常重要的原因:BucketCache 是为了解决之前 BlockCache 这种 on-heap 缓存方案造成的 GC 性能问题而诞生,本质上也还是一个缓存,既然是缓存就必定要考虑缓存数据的驱逐,因此 BucketCache 的设计方案中包含如何释放内存以及合并 bucket 的逻辑。但是正排索引不是缓存,也就不存在驱逐数据的问题4,BucketCache 中的这部分设计对于我们的场景来说其实是多��余的,如果完全照搬反而是在系统中引入了一个不必要的复杂组件,增加维护成本5。因此我们最终借鉴了一部分 BucketCache 的设计思想同时再结合推荐系统的业务特点实现了一个只读版本的堆外内存,下图是具体的实现方案。
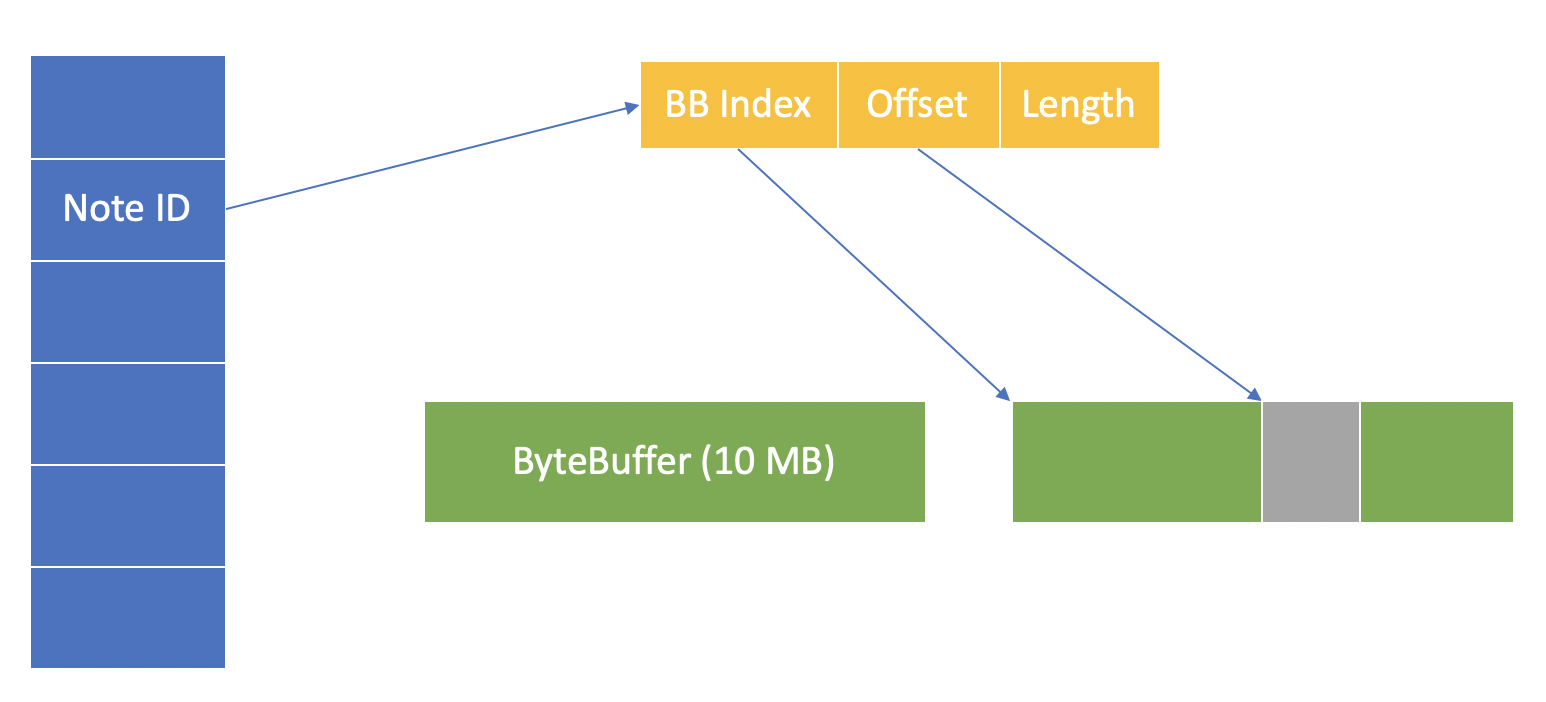
上图中最左边蓝色的部分是一个 hash map,key 是正排索引的主键,value 是一个包含与堆外内存地址有关的元信息对象。这个元信息对象中主要有 3 个成员变量:
- BB Index:BB 是
java.nio.ByteBuffer的缩写,是 Java 中创建堆外内存的底层 API。在应用的初始化阶段我们会提前申请一块儿大的物理内存空间作为堆外内存,假设这块儿内存的大小是 10GB,在其中会按照一个固定的大小(默认是 10MB)再分割成多个小的 bucket。BB Index 即是某个 bucket 的索引。 - Offset:每个 bucket 中存储了很多正排索引条目,offset 是某个条目在当前 bucket 中的偏移。
- Length:这个很好理解,就是索引条目的长度。
上图中蓝色和黄色的部分还是存储在堆内,只有绿色部分属于堆外。写入数据的流程就是根据索引条目的长度找到空闲的 bucket,然后通过 ByteBuffer.put() 方法将数据存放到堆外内存,并在 hash map 中新增相应的元信息。读取数据的流程是首先查找元信息,然后通过 HBase 中封装的 UnsafeAccess.copy() 方法将数据从堆外拷贝到堆内。当然数据拷贝出来以后并不能直接使用,因为这还只是序列化后的字节流,还需要经过反序列化步骤6。
二级索引
二级索引的概念在很多数据库系统中也存在,特别是分布式数据库,通常主键用来查询分片的位置,而二级索引用来在某个具体的分片中查询特定的字段。
在推荐系统场景中二级索引的功能类似,只不过不是因为这是一个分布式系统,而是为了查询某些特殊的特征。在传统的机器学习模型中有一类特征是非常重要的,那便是内容在不同维度的统计值。举个例子,我们不仅会统计一篇笔记的总曝光数,还会统计这篇笔记在不同城市、不同性别、不同类型设备的曝光数,这里的城市、性别、设备类型就是维度。并且这些维度是允许交叉的,也就会产生非常多的维度组合。所有这些维度组合起来的统计值是一个大的集合,每次查询时并不需要这个集合中的所有值,而是根据当前用户的画像选取与这个用户相符的值。
如果每次查询时都把所有值从堆外内存中拷贝出来显然是很浪费的,因此我们需要一种方法直接从堆外内存中查询部分值,这就是二级索引的作用。二级索引的字段在 schema 中会标记 secondary_key 属性,上一篇文章中示例的字段类型是 [BreakdownStats],那这个 BreakdownStats 的定义是什么呢?如下所�示:
table BreakdownStats {
key:SecondaryKey (id: 0);
value:NoteEngagementStats (id: 1);
}
上面 key 字段的数据类型是 SecondaryKey,这是一个由框架预定义的类型,具体定义如下:
table SecondaryKey {
type:int (id: 0);
value:string (id: 1);
}
因此我们可以知道一个二级索引 key 由两部分组成:type 和 value,type 是 key 的类型(通常是可枚举的),value 是具体的值(不可枚举)。继续拿前面的例子举例,「城市」是一种 key 的类型,「上海」是具体的值。于是查询流程相比前面介绍的区别之处在于,通过主键查找以后还需要通过二级索引 key 才能获取到元信息对象,相当于增加了一次 hash map 的查找。一个优化的细节点是在框架内部我们还将二级索引 key 映射到了一个整数,这样便可以将这个整数作为 hash map 的 key 来使用。于是通过刚才的流程便实现了直接获取某个维度(或者维度组合)的统计值的需求。
以上就是本篇要介绍的全部内容,简单回顾一下:
- 基于堆外内存的正排索引
- 通过二级索引实现查询部分特征
至此两种索引已经全部介绍完毕,下一篇文章将会围绕一个更加上层的问题「索引如何快速更新」进行讨论。数据不可能是一成不变的,更新的效率也会直接影响产品体验和业��务指标。
Footnotes
-
训练数据往往是用户的历史行为数据,例如用户看过、点过、赞过、评论过的所有内容。 ↩
-
除了堆外内存这种方案还有一些其它可参考的解决方案,例如阿里巴巴曾经分享过的一些经验(文章中提到的 AliGC 多租户功能近期已经在 Alibaba Dragonwell 8.3.3-GA 中开源);Netflix 的开源框架 Hollow。 ↩
-
BucketCache的详细设计可以参考 HBASE-7404 这个 issue ↩ -
本质上索引是只读的 ↩
-
也许有人会问索引数据难道是不更新的吗?答案是需要更新,有关如何更新索引数据会在下一篇文章中介绍。 ↩
-
频繁从堆外拷贝大量数据并反序列化可能会是一个比较耗时的过程,因此我们在实际使用时还在正排索引上增加了一层堆内的缓存。 ↩