如何设计与实现一个分布式索引框架(五):分布式
这是一个系列文章,大部分内容都来自我过去在小红书发现 Feed 团队工作期间的实践和经验。在介绍的过程中我会尽量不掺杂过多的业务细节,而专注于这背后我个人一些浅薄的设计思想,希望你在阅读完这些文章以后能够直接或者间接地拓展到不同的场景。
前面几篇文章介绍的技术都是在单机上实现的,但如果做不到分布式那整个系统的扩展性将会受到非常大的限制。本篇文章将会围绕分布式这个话题讨论。
数据分割(Partition)
分布式存储很大��一个目的是为了将数据分布到多个节点上,以突破单机的存储限制,实现水平扩展(horizontal scaling)。因此这就涉及到一个很重要的问题:要如何将数据分布到不同的节点上?可能的几种做法有:
- 随机:每一条数据都随机分配到某个节点上
- 轮询(round-robin):通过轮询的方式将数据分配到节点上,例如第 1 条数据分配到节点 1,第 2 条数据就分配到节点 2,以此类推。
- 哈希(hash):通过某种哈希算法将数据中的某个 key 映射到一个固定的值,根据这个值来分配节点。
- 范围(range):划定一些范围,并将这些范围与节点进行映射,当数据中的某个 key 属于某个范围时就分配到对应的节点上。
方案 1 显然是最简单的,但也是最不可行的。这个方案有两个大问题:因为数据是随机分配的,因此在查询某一条数据时必须请求所有节点;同样因为随机分配的关系,不同节点之间的数据量可能是非常不均衡的。
方案 2 相比方案 1 稍微改进了一点,轮询的方式可以基本保证数据分布是均衡的,但是在查询时还是必须请求所有节点。
方案 3 基本解决了前面提到的两个问题,哈希算法通常是稳定的,也就是说通过某个 key 得到的哈希值是固定的。比如最简单的哈希算法取模运算,将 key 模上集群的节点数 key mod N,就可以算出这个 key 应该分配的节点。不过取模运算虽然简单但也存在一些问题,最明显的就是当添加新节点或者删除老节点的时候会造成大量的数据重新分配(rebalance)。因此比较常见的改进方案是采用一致性哈希(consistent hashing),一致性哈希可以显著降低数据重新分配这个过程需要迁移的数��据量。Amazon 的 Dynamo 便是采用一致性哈希进行数据分割的一个很好的例子,Cassandra 的官方文档里也介绍了类似的内容。但是一致性哈希也不是没有缺点,当集群节点数较少时还是有可能造成数据分布不均衡,因此 Dynamo 提出了通过增加虚拟节点(virtual node)的方法来解决这个问题,细节可以参考论文或者 Cassandra 的文档。
方案 4 也能实现稳定查询,例如将数据 key 的首字母限定在 a-z 这 26 个字母中,再将 a-z 等分为几个范围(range),那么就能根据 key 的首字母确定属于哪个范围。同时每个节点会包含 1 个或多个范围,便能将 key 分配到某个节点上。HBase 便是采用范围分割数据的一个案例,但是由于 HBase 不会预先为所有节点绑定范围,因此在实践中通常还要结合 pre-split 来避免数据都集中在少数节点中。因为每个范围都是连续的,所以方案 4 相比方案 3 的一个优势是对于范围扫描(range scan)的支持更好。
综合来看方案 3 和方案 4 都是可行的方案,它们也都有各自的一些优缺点,如何选择还得看具体的使用场景。
数据复制(Replication)
数据分布到多个节点上以后,虽然扩展性(scalability)得到了满足,但是随着节点数的增多,可用性(availability)的重要性会逐渐�凸显出来。节点因为各种原因下线是非常普遍的,一旦节点下线那这台节点上的数据将无法访问。因此为了保障可用性,通常会通过冗余存储的方式来解决,也就是为每一份数据新增多个副本(replica),然后将副本分散到不同的节点上,只要还有至少 1 个副本存在那即使部分节点下线也能继续访问数据。为了实现多副本也有几种可能的方案:
- 节点组(node group):为每个节点创建多个副本节点,这些节点共同组成一个节点组。一个节点组内部的数据是完全相同的,不同节点组之间的数据是不同的。
- 混合(hybrid):每个节点不仅有属于自己的数据,同时还存储了其它节点数据的副本。
方案 1 中节点组之间的数据因为是相互独立的,因此实现和维护相对来说都会比较简单,新增副本就只需要在每个节点组中新增节点即可。我们在数据库系统中经常见到主(master)从(slave)节点的概念,这里可以把 1 个主节点和多个从节点看作是一个节点组。
方案 2 是目前主流分布式存储的实现方案,在存储数据时通过某种算法选择多个副本节点,并时刻检查当前数据的副本数是否符合用户设定的值。这种方案因为在一个节点上同时包含了原始数据和副本,相比方案 1 节点的资源利用率会更高,但代价就是维护成本会有所提升。
不论是选择前面介绍的哪种方案都会涉及到一个问题:如何将原始数据同步到副本上?这里就必须提及在分布式系统中非常重要的一个概念「一致性(consistency)」1,所谓一致性就是用于描述分布式系统中不同实体间状态(state)一致程度的概念。一致性从强到弱大致可以分为��以下 4 种类别:
- 线性一致性(Linearizability)或者强一致性(Strong consistency)
- 顺序一致性(Sequential consistency)
- 因果一致性(Causal consistency)
- 最终一致性(Eventual consistency)
一致性越强的算法对数据的一致要求也越高,当然实现成本也越高。线性一致性的代表有 Paxos 和 Raft,最终一致性的代表有 Dynamo2。为什么一致性如此重要呢?因为分布式系统天然存在的并发和延迟,要如何把一个集群的状态更新最终实现得看起来就像一台单机一样,这是一致性算法要解决的问题。
具体细分状态复制的实现方式有两种:一种是传统的 replicated state machine(或者叫做 active replication),另一种是 primary-backup(或者叫做 primary-copy、passive replication)。前者的代表有 Paxos 和 Raft,后者的代表有 Viewstamped Replication 和 Zab(ZooKeeper Atomic Broadcast)。有关这两种状态复制方案的区别可以看看 Raft 作者的博士毕业论文3和 Vive la Différence: Paxos vs. Viewstamped Replication vs. Zab 这篇论文。
因此回到最开始的那个问题「要如何将原始数据同步到副本」,这取决于你需要哪种程度的一致性,你甚至可以说我不需要一致性4。对于推荐系统的场景,线性一致性属于杀鸡用牛刀5,所以我们只要追求最终一致性就够了。
集群成员管理
一个分布式系统必然是由多个节点构成的,那这些节点之间要如何互相感知呢?关于这个问题可以分为两类方案:中心化和去中心化。
所谓中心化就是存在一个(或一组)集中管理的服务,这个中心服务负责接收并存储集群所有节点上报的信息,以及反向分发这些信息,相当于一个集群的信息枢纽。在微服务领域有另外一个词用于表示类似的功能:服务注册与发现。常见的可以实现这种中心服务的开源组件有 ZooKeeper、etcd 和 Consul。
而去中心化顾名思义就是不存在一个中心服务,完全依靠集群内各个节点之间的通信来实现拓扑发现。最著名的去中心化协议恐怕就是 gossip 协议,这是一个可以实现点对点(P2P)通信的协议,很��多开源系统里也使用到了 gossip,比如 Cassandra 和 Consul。
至于是中心化还是去中心化好那只能是见仁见智了,没有哪个方案是绝对完美的。
数据重新分配(Rebalance)
前面的「数据分割」小节已经介绍了如何将数据分布到不同的节点上,如果一个集群的节点数永远不变那这不会带来任何问题,但是如果存在新增或者删除节点的情况呢?不论是哈希还是范围分割的方法,都必须要重新分配数据,以保持集群节点间的数据均衡。为了不影响已有的节点,数据重新分配通常的实现都是在一个后台线程中执行,同时也要控制数据同步的带宽和速率。当数据重新分配这个过程完成以后就可以上线或者下线对应的节点。
当然数据重新分配也不一定就只是由集群节点伸缩触发的,某些系统也会实时地根据当前每个节点的负载而动态调整数据的分布,目的是为了避免出现热点导致整体系统的稳定性受影响。
整体设计
综合前面介绍的所有内容,现在如果让你来设计分布式索引你会如何设计?这里提供一个我们的实现方案,但是请记住一定不存在一个完美的方案,任何架构�设计都是权衡(trade-off)的结果。
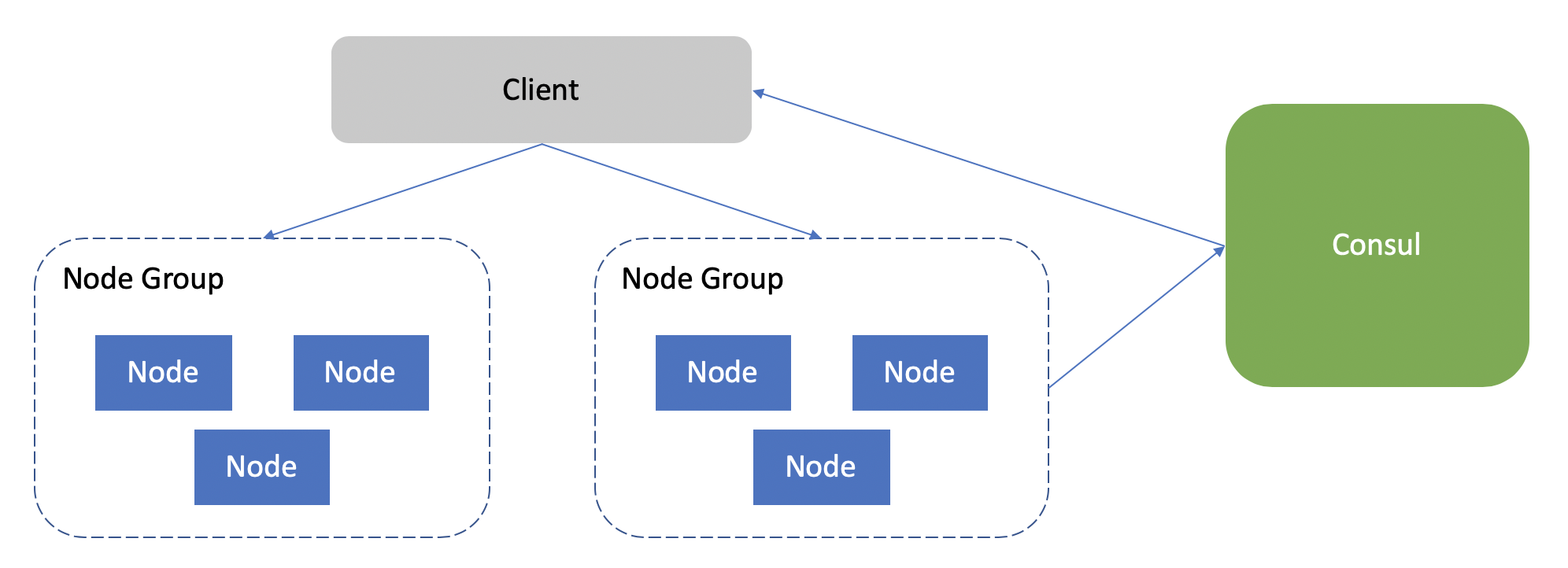
简单总结上面这个方案的一些特点:
- 通过哈希来进行数据分割
- 通过节点组的方式进行数据复制,一致性的要求是最终一致性6。
- 通过 Consul 来进行服务注册和发现,并封装一个库供客户端使用。
以上就是关于分布式的介绍,下一篇文章的内容会相对轻松一些,聊一聊所谓的端到端(end-to-end)用户体验。