如何设计与实现一个分布式索引框架(四):索引更新
这是一个系列文章,大部分内容都来自我过去在小红书发现 Feed 团队工作期间的实践和经验。在介绍的过程中我会尽量不掺杂过多的业务细节,而专注于这背后我个人一些浅薄的设计思想,希望你在阅读完这些文章以后能够直接或者间接地拓展到不同的场景。
上一篇文章介绍了如何实现正排索引和二级索引,但要创建索引也得先有数据才行,本篇将会介绍数据是如何更新的。
全量索引
所谓「全量索引(full index)」就是指需要索引的数据的全集,通常全量索引的数据量都是一个比较大的量级1,离线构建一次全量索引的时间成本也比较高,因此更新频率不会特别频繁2。全量索引的更新很简单,一般就是覆盖线上已经存在的那份旧的全量索引,当然这个更新流程不会是直接替换,而是先把新的数据加载好再进行替换,也就是说在更新的过程中需要保证内存中能够同时存放两份数据。
全量索引有几个比较严重的问题:
- 索引的数据量决定了它的更新频率不会很快,而且有变化的数据在这个全集中必定是少数,每次都更新全部数据有点浪费。
- 索引更新过程中需要临时存储双份数据,会有大量新对象产生,对 GC 的压力也会很大。很多时候我们选择不频繁更新全量索引也是这个原因,这就进一步加剧了上一个问题的影响。
解决思路其实也很直接,既然需要更新的数据是少数,那每次索引更新就只更新这部分数据好了,这也就是下一章节要着重介绍的内容。
增量索引
与「全量索引」一起经常被提及的另一个词就是「增量索引(incremental index)」,顾名思义增量索引是只针对增量数据构建的集合,因此索引的数据量也会小非常多,自然更新频率就可以很快了。构建增量索引并不是一件特别复杂的事情,只需要有办法获取到最近一段时间有变化的内容就行3。但是构建好的增量索引要如何更新到线上是一个值得认真思考的问题,有两种方案可以选择:
- 直接修改全量数据的倒排索引和正排索引
- 单独为增量数据创建倒排索引和正排索引
第 1 种方案如果是新增的内容比较简单,在倒排索引和正排索引中插入新的条目即可。但如果是旧的内容被更新或者删除,那就需要在这两种索引中找到对应的条目并全部更新或者删除。直接原地更新或者删除对于倒排索引来说因为需要扫描整个索引条目列表,时间复杂度会随着列表长度以及增量更新的数据量线性增长;对于正排索引来说堆外内存不可避免会产生空间碎片,必须定期清理碎片以免造成空间浪费。
第 2 种方案创建索引的逻辑跟全量索引是一样的,只不过是针对增量数据。但是此时相当于就存在了多个倒排索引和正排索引,查询逻辑应该怎样实现呢?由于正排索引是一一映射,因此如果有多个相同 primary key 的索引,那在查询时选择最新的那个索引即可。查询倒排索引稍微复杂一点,同一个倒排索引 key 可能在多个索引中都存在,查询时需要同时从这些索引中遍历,最终选取出 top N 的条目4。遍历时除了用户提供的过滤器以外,还需要过滤那些已经被删除的条目,这可以通过一个全局的已删除条目集合来实现。随着增量索引数量的增多,不同索引间冗余的数据会变得越来越多,浪费存储空间的同时也会增加查询的时间复杂度。因此我们需要不定期合并这些索引,去除那些重复或者被删除的条目。
我们最终选择了方案 2,因为整体上更倾向于把存储的数据结构设计成 append-only 的模式,简化底层存储的实现5。熟悉数据库系统设计的朋友可能已经发现方案 2 同现在流行的 LevelDB、RocksDB 有一些相似的地方,事实上我们在设计时也的确借鉴了它们的部分思想。这两者底层都是 LSM tree 的数据结构,简单介绍 LSM tree 就是将数据分为多个 level,每个 level 的数据都是只读的且可能存在冗余,不同 level 之间会通过压缩(compaction)来去掉这些冗余。下图是增量索引的设计示意图。
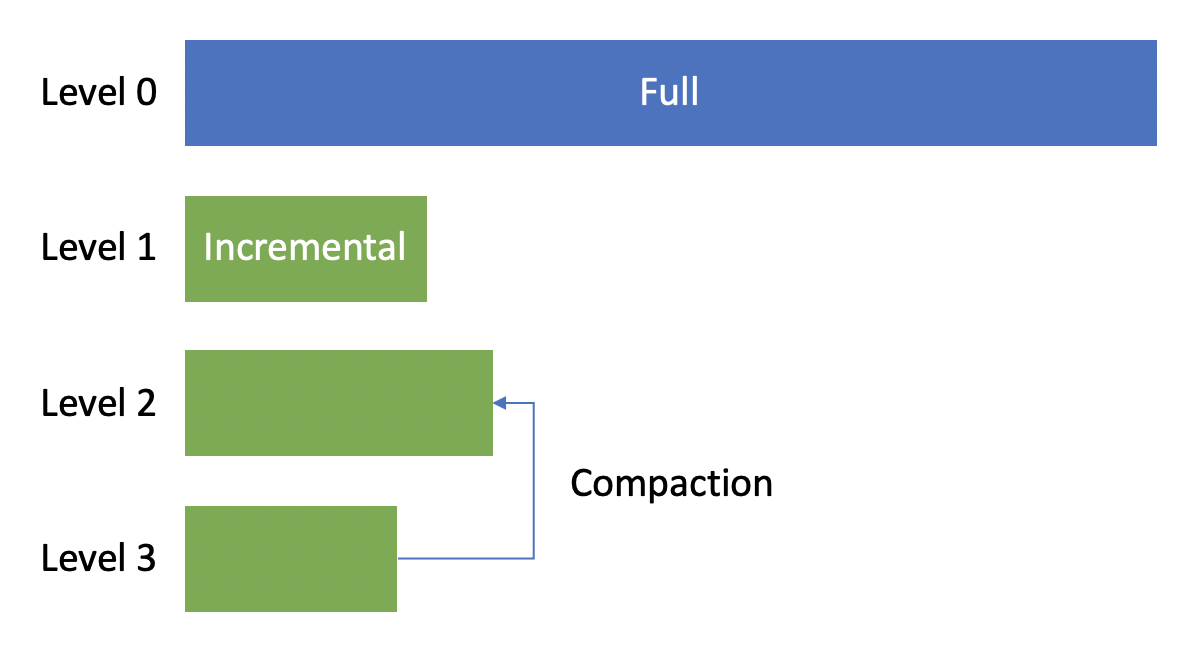
我们限定最大的 level 数(即增量索引数),如果超过这个限定值就会触发合并。大部分情况下都会是增量索引之间进行合并,但如果合并之后的大小已经超过全量索引大小的某个比例,就会触发 1 次同全量索引的合并。
有了增量索引之后索引的更新频率最快可以控制在分钟级,相比全量索引动辄小时级甚至天级的频率已经快了不少。索引更新更快也意味着内容可以更快地被用户消费,促进了整个社区的信息流动。
以上就是本篇要介绍的全部内容,简单回顾一下:
- 全量索引虽然构建成本很高但也是不可或缺的,它有着最全的业务数据。
- 增量索引的目的是为了��加快索引更新频率,设计上借鉴了部分 LSM tree 的思想。
注意过这个系列文章标题的朋友可能很好奇讲了这么久为啥感觉跟分布式一点儿关系都没有,的确前面几篇文章都是在重点介绍索引相关的技术,下一篇文章将会开始聊聊分布式这个话题,敬请期待。
Footnotes
-
当然数据量有多大取决于你的业务数据有多少 ↩
-
小时级、天级、周级都有可能 ↩
-
如何获取有非常多的方案,比如 MySQL 的 binlog,MongoDB 的 oplog。基础服务做得比较好的公司还会将不同存储的更新消息聚合到类似消息队列的系统中,方便下游业务消费。 ↩
-
假设现在有 3 个倒排索引,那是不是得从这 3 个倒排索引中都选出 top N 以后才能得到最终的结果呢(即总共需要查询 3 x N 个条目)?答案是不用,一种优化的实现方案是同时比较 3 个倒排索引的头部,挑选最大的那个条目,然后一直重复这个步骤直到满足选出 N 个条目,这样总共需要查询的条目数仍然是 N。 ↩
-
比如堆外内存从设计上就不用考虑更新和删除操作 ↩